
Biology 3: Chemical Bases of The Life 2
Content
• Nucleic acids
• Proteins
If you have not seen the first part of this article where it talks about dehydration synthesis, hydrolysis, carbohydrates and lipids, we recommend that you read it before reading this article, since we will mention what was mentioned in the previous article .
Nucleic Acids
Nucleic acids, macromolecules made up of units called nucleotides, exist in a variety of forms which most common are: deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). DNA is the genetic material of living organisms, from single bacterias to multicellular organisms. Some viruses use RNA, not DNA, as their genetic material, but they are not considered live beings.
In eukaryotic organisms, such as plants and animals, DNA is found in the nucleus, a specialized membrane-enclosed space inside the cell, as well as in certain different organelles (such as mitochondria and chloroplasts) this last one can find its origin in the endosymbiotic theory, of which we will speak in more detail in another article.
In prokaryotic organisms, such as bacteria, DNA is not enclosed in a membranous envelope but directly in contact with the cytoplasm, although it is found in a specialized region of the cell called the nucleoid.
In eukaryotic organisms, DNA is usually separated into a number of very long linear fragments called chromosomes, while in prokaryotes, such as bacteria, the DNA is usually found on its free form (lineal form). A chromosome can contain tens of thousands of genes, each providing instructions on how to make a particular product that the cell needs.
Many genes present in DNA and/or RNA are responsable for the coding of protein products, which means, they indicate the amino acid sequence that is used to build certain protein in particular. However, before this information can be used for protein synthesis in different organelles, a copy of the gene must first be made in the form of an RNA molecule, this type of RNA is called messenger RNA (mRNA) and serves as a messenger between DNA and ribosomes to synthesize proteins. This progression from DNA to RNA to protein is what is known as the "central dogma" of molecular biology.
It is important to note that not all genes code for protein products. For example, some genes encode ribosomal RNA (rRNA), which serves as a structural component of ribosomes, or transfer RNA (tRNA), which are cloverleaf-shaped RNA molecules that transport amino acids to the ribosome for protein synthesis. Even other RNA molecules, such as micro RNA (known as miRNA), which act as regulators of other genes.
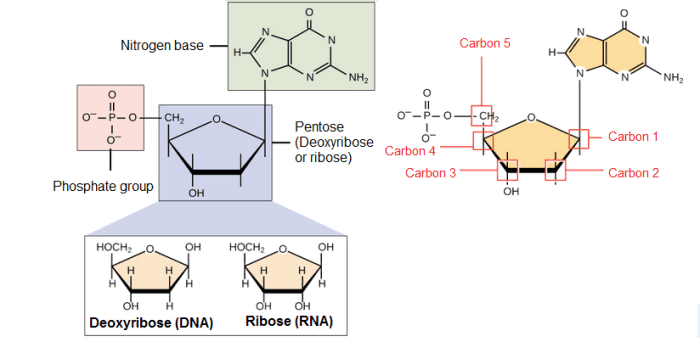
Nucleotides: DNA and RNA are polymers, which means, molecules made up of monomers known as nucleotides. When these monomers combine, the resulting chain is called a polynucleotide or nucleic acid.
Each nucleotide is made up of three parts: a nitrogen-containing ring structure called a nitrogenous base, a five-carbon sugar called pentose, and at least one phosphate group. The sugar molecule has a central position in the nucleotide, the base is connected to one of its carbons and the phosphate group (or groups) to another.
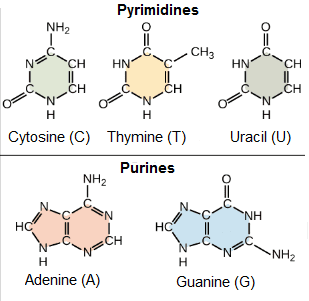
Nitrogenous bases: They are organic molecules (based on carbon), composed of ring structures that contain nitrogen. Each nucleotide in DNA contains one of four possible nitrogenous bases: Adenine (A), Guanine (G), Cytosine (C), and Thymine (T). Adenine and guanine are purines, which means that their structures contain two fused rings of carbon and nitrogen. Instead, cytosine and thymine are pyrimidines and have only one carbon and nitrogen ring.
RNA nucleotides on the other hand, can also contain adenine, guanine and cytosine bases, but have another pyrimidine-like base called Uracil (U) instead of Thymine. Each base has a unique structure, with its own set of functional groups attached to the ring structure.
As abbreviations in molecular biology, nitrogenous bases are often named by their one-letter symbols: A, T, G, C, and U.
Pentoses: DNA and RNA nucleotides have slightly different sugars, the pentose in DNA is called deoxyribose, while in RNA the pentose is ribose. These two molecules are similar in structure, with only one difference; the second carbon in ribose has a hydroxyl group, while the equivalent carbon in deoxyribose has a hydrogen instead, so it is said to have less oxygen, thats why it's name (deoxyribose).
The carbon atoms of a sugar molecule are numbered 1, 2, 3, 4, and 5, and in a nucleotide, the sugar occupies the central position, with the base bound to it's carbon 1, and the phosphate group (or groups) bound to it's carbon 5 '.
Phosphate group: Nucleotides can have only one phosphate group or even a chain of three phosphate groups that are attached to carbon number 5 of ribose.
In a cell when the nucleotide that will be added to the end of a polynucleotide chain contains a series of three phosphate groups, it loses two phosphate groups when the nucleotide joins the growing chain of DNA or RNA. Therefore, in a DNA or RNA strand, each nucleotide can only have one phosphate group.
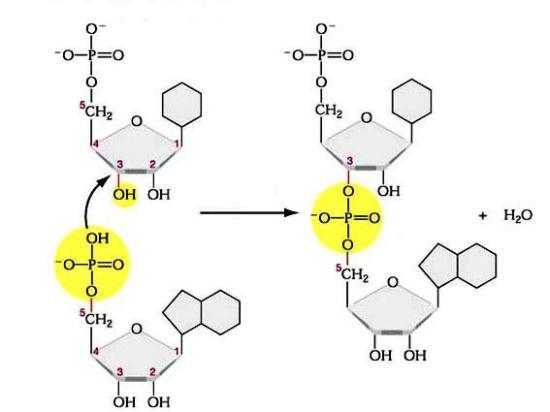
Polynucleotide chains: A consequence of the nucleotide structure is that a polynucleotide chain has directionality, which means, it has two ends that are different from each other and that when linked give a certain shape to the nucleic acid structure. At the beginning of the chain (Carbon 5) the phosphate group that's attached to carbon number 5 of the first nucleotide stands out. At the other end, the hydroxyl group of pentose attached to carbon 3 of the last nucleotide is exposed.
DNA sequences are generally written in the 5 to 3 direction, which means that the nucleotide at the 5 end is first and the nucleotide at the 3 end is last.
As new nucleotides are added to a DNA or RNA strand, it grows at its 3-end, when phosphate 5 of the incoming nucleotide is attached to the hydroxyl group at the 3-end of the strand. This produces a chain in which each sugar is joined to its neighbors by a series of bonds called phosphodiester bonds.
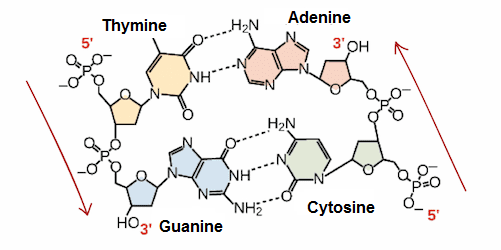
Characteristics of DNA: In deoxyribonucleic acid, or DNA, the chains are normally found in a double helix, a structure in which two paired (complementary) chains are joined together through the hydrogenated bases with a bond called the hydrogen bridge.
Sugars and phosphates are found on the outside of the helix and constitute the backbone of DNA; This part of the molecule is often called the sugar-phosphate backbone while the nitrogenous bases extend inwards in pairs like the rungs of a ladder.
The way in which these nitrogenous bases are connected is through hydrogen bridges, however for this to be possible the chains that form the helices must be corresponding, which means, they need to have compatible nitrogenous bases. This compatibility to bind is called codon and anticodon. Where if you have a nitrogenous base Adenine (codon), its complement would be a nitrogenous base Thymine (anticodon).
Codons and anticodons are only necessary in DNA, since RNA does not form a double helix, so the nitrogenous base pairs are A - T (or vice versa), and G - C (or vice versa).
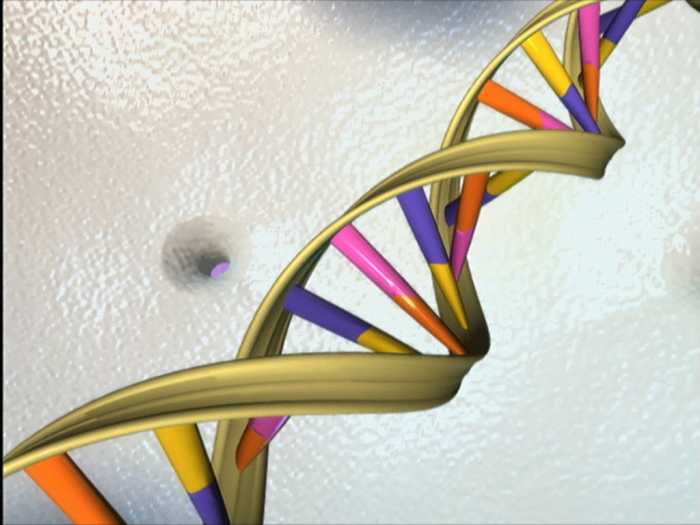
Characteristics of RNA: Unlike DNA, ribonucleic acid, or RNA, is generally of one helix. The nucleotide of an RNA strand will have a ribose, one of the four nitrogenous bases (A, U, G, and C), and a phosphate group. However, there are four main types of RNA: messenger RNA (mRNA), ribosomal RNA (rRNA), transfer RNA (tRNA), and regulatory RNAs.



- Messenger RNA (mRNA): this is an intermediate between a gene that codes for proteins and the protein itself, serving as a kind of instructive that indicates the order of amino acids for the construction of the protein. If the cell needs to make a particular protein, the gene that codes for the protein will be "turned on", meaning that a polymerizing RNA enzyme will make an RNA copy of the gene's DNA sequence, this process is known as DNA transcription. The RNA copy, also known as a transcript, contains the same information as the DNA sequence of your gene. However, in the RNA molecule, the base T is substituted for U since it is impossible for an RNA strand to have thymine, and this is substituted for Uracil. For example, if a DNA coding strand has the sequence 5-AATTGCGC-3, the corresponding RNA sequence will be 5-AAUUGCGC-3. Once an mRNA has been produced, it will travel through the cytoplasm and associate with a ribosome (a molecular organelle that specializes in making proteins from amino acids). The ribosome will then use the information from the mRNA to form a protein with a specific sequence by "reading" the nucleotides from the mRNA.
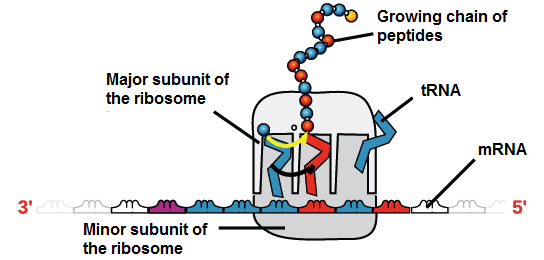
- Ribosomal RNA (rRNA): It is one of the main components of the ribosome and helps the mRNA bind to the proper site so that its sequence information can be read. Some rRNAs also act as enzymes, that is, they help speed up (catalyze) chemical reactions; in this case, they help form the bonds that join amino acids to form a protein within the ribosome, these last types of rRNA that function as enzymes are known as ribozymes.
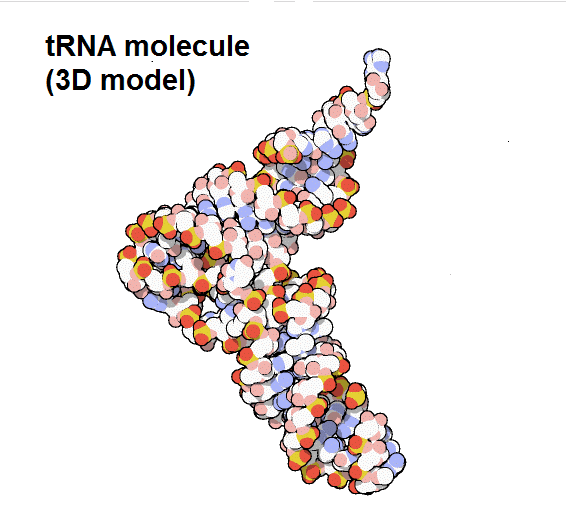
- Transfer RNA (tRNA): These also participate in protein synthesis, but their job is to serve as carriers, so they are responsible for carrying amino acids to the ribosome to ensure that the amino acid that is added to the chain is the one that specifies the mRNA. Transfer RNAs are made up of a single strand of RNA, but this contains complementary segments that join together to form double helix regions in which amino acids are hold; this base pairing creates a complex 3D structure that commonly resembles a clover, and is very important to the function of the molecule.
- Regulatory RNAs (miRNA and siRNA): Some types of non-coding RNA (which does not code for proteins) help regulate the expression of other genes. Such RNA molecules can be called regulatory RNAs. For example, microRNAs (miRNAs) and interference RNAs (siRNAs) are small regulatory RNA molecules approximately 22 nucleotides long. They bind to specific mRNA molecules (with partially or fully complementary sequences) and reduce their stability or interfere with their translation and thus provide the cell with a way to reduce or fine-tune the concentration of these mRNAs. These are just a few examples of many types of noncoding and regulatory RNAs. Scientists are still discovering new varieties of noncoding RNA.
In addition to DNA and RNA, nucleotides can be found in their free form that fulfill their own function, an example is the molecules of ATP (adenosine triphosphate), a molecule that is used in the body as energy, among many others.
Proteins
Proteins are one of the most abundant organic molecules in living organisms and are much more diverse in structure and function than other classes of macromolecules. A single cell can contain thousands of proteins, each with a unique function. Although their structures and functions vary widely, all proteins are made up of one or more chains of amino acids.
Enzymes: Enzymes act as catalysts in biochemical reactions (that is, they accelerate them). Each enzyme recognizes one or more substrates, the molecules that serve as the starting material for the reaction it catalyzes. Different enzymes participate in different types of reactions and can break down, bind, or rearrange their substrates.
An example of an enzyme found in your body is salivary amylase, which breaks down amylose in food into smaller sugars. Amylose does not taste very sweet, but the smaller sugars do. That's why starchy foods are sweeter if you chew them longer, you're giving salivary amylase time to do its job.
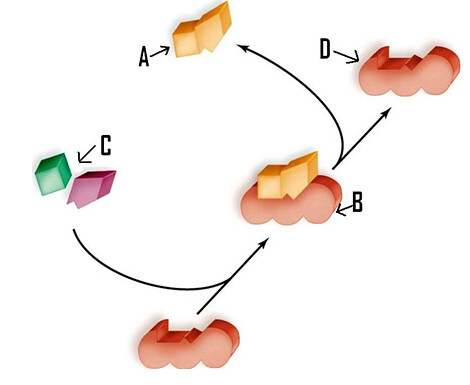
Hormones: Hormones are long-distance chemical signals released by endocrine cells that control specific physiological processes, such as growth, development, metabolism, and reproduction. While some hormones are steroid-based, meaning they are lipids, others are proteins. These protein-based hormones are called peptide hormones.
For example, insulin is an important peptide hormone that helps regulate blood glucose levels, it is produced by the pancreatic beta cells, which travel throught the organism to allow the cells absorb glucose. This process allows blood glucose to return to normal levels at rest.
Types of proteins and their functions
| Type | Examples | Functions |
|---|---|---|
Digestive enzyme | Amylase, lipase, pepsin | It breaks down the nutrients in food into smaller pieces that can be easily absorbed. |
Transport | Hemoglobin | It carries substances through the body in the blood or lymph. |
Structure | Actin, tubulin, keratin | It forms different structures, such as the cytoskeleton. |
Hormonal signaling | Insulin, glucagon | Coordinates the activity of different body systems. |
Defending | Antibodies | Protects the body from external pathogens. |
Contraction | Myosin | Carries out muscle contraction. |
Storage | Albumin | It provides food for the early development of plants and chicken embryos (as it is found in the egg as well). |
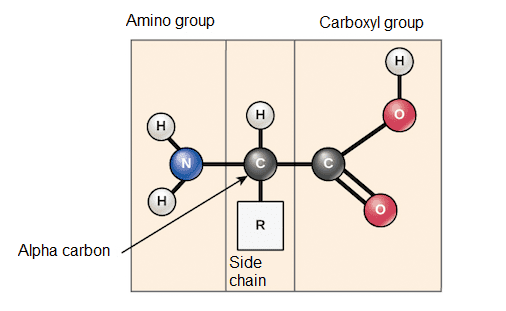
Amino acids: Amino acids are the monomers of wich proteins are formed, however the chain needs to reach a size greater than 200 amino acids to be considered a protein, otherwise it is called "peptide". Proteins contain 20 types of amino acids within their structure, since they are the most common types of amino acids that exist.
Amino acids share a basic structure consisting of a central carbon atom, also called alpha carbon (α), attached to an amino group (NH2), a carboxyl group (COOH) and a hydrogen atom, in addition to its radical chain (R). The amino group is generally protonated and has a positive charge, while the carboxyl group is deprotonated and has a negative charge.
The R group is a chain that determines the identity of the amino acid. For example, if the R group is a hydrogen atom, the amino acid is glycine, while if it is a methyl group (CH3), the amino acid is alanine. The 20 common amino acids are shown in the table below, with their R groups.
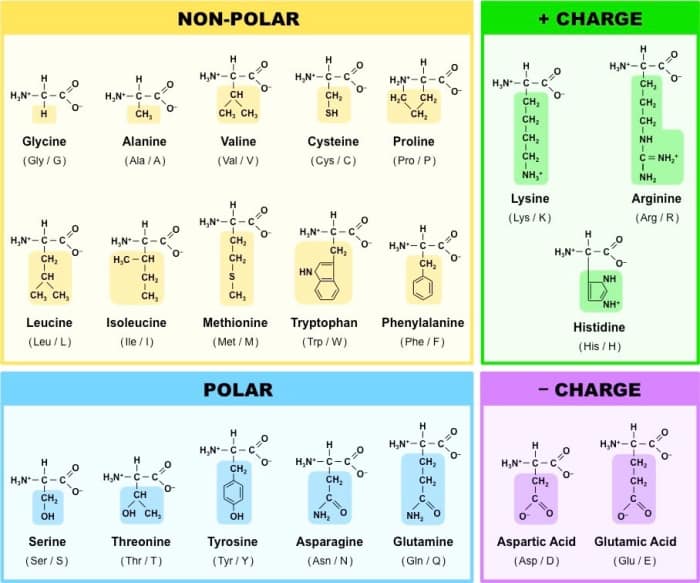
Side chain properties determine the chemical behavior of an amino acid (whether it is considered acidic, basic, polar, or nonpolar). For example, amino acids like valine and leucine are nonpolar and hydrophobic, while amino acids like serine and glutamine have hydrophilic side chains and are polar. Some amino acids, such as lysine and arginine, have side chains that are positively charged at physiological pH (greater than 7) and are considered basic amino acids. Aspartate and glutamate, on the other hand, are negatively charged at physiological pH (less than 7) and are considered acidic amino acids.
Some other amino acids have R groups with special properties, for example proline has an R group that is attached to its own amino group, forming a ring structure, it is an exception to the typical structure of an amino acid, since it does not have the usual amino group, and thanks to its ring shape, proline often causes amino acid chains to bend or twist; Another exception is that cysteine contains a thiol group (-SH) and can form covalent bonds with other cysteines. Finally, there are other "non-canonical" amino acids that are found in proteins only under certain conditions.
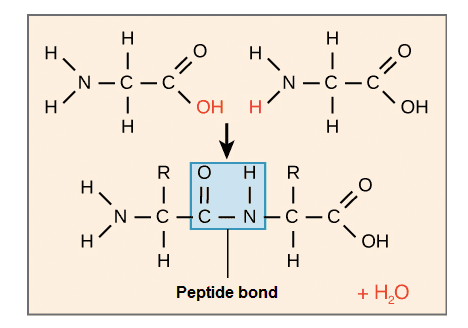
Peptide bonds: Each protein in cells consists of one or more polypeptide chains, each of which is made up of amino acids linked in a specific order. The chemical properties and order of amino acids are key in determining the structure of the protein.
The amino acids of a peptide or protein are linked to their neighbors through a covalent bond known as a peptide bond, which is formed in a dehydration synthesis reaction, that is, it releases a water molecule. During protein synthesis, the carboxyl group of the amino acid at the end of the growing polypeptide chain reacts with the amino group of an incoming amino acid, releasing a water molecule. The resulting bond between amino acids is a peptide bond.
Given the structure of amino acids, a polypeptide chain has directionality, which means that it has two ends that are different from each other at the chemical level. At one end, the polypeptide has a free amino group, called the amino terminal (or N-terminal end). The other end, which has a free carboxyl group, is known as the carboxyl terminal (or C-terminal end).
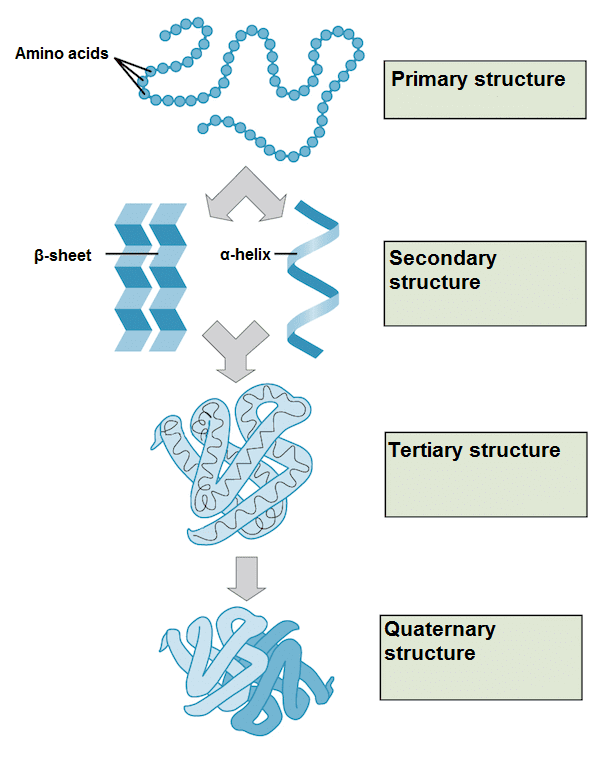
Primary structure: It is the simplest level of structure of a protein, it is simply the sequence of amino acids in a polypeptide chain.
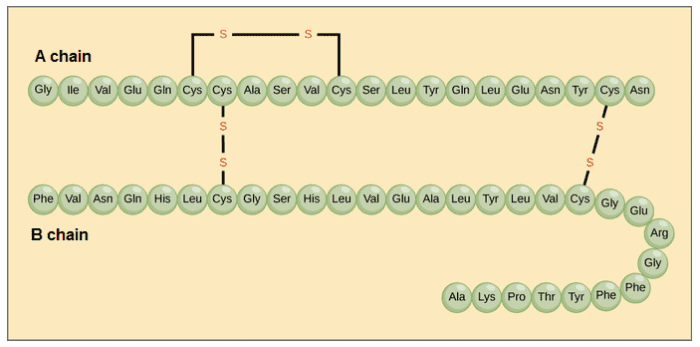
The sequence of a protein is determined with the DNA of the gene that encodes it (through transcription). A change in the DNA sequence of the gene can modify the amino acid sequence of the protein. Even changing just one amino acid in the protein sequence can affect the overall structure and function of the protein.
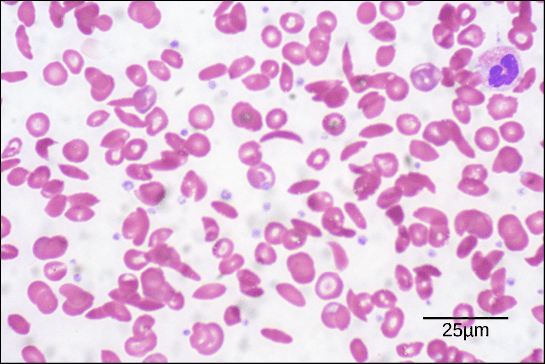
For example, in cell with sickle anemia, one of the polypeptide chains that make up hemoglobin, the protein that carries oxygen in the blood, has a slight change in sequence. Glutamic acid, which is normally the sixth amino acid in the β chain of hemoglobin (one of two types of protein chains that make up hemoglobin), is replaced by a valine.
A hemoglobin molecule is made up of two α chains and two β chains, each with about 150 amino acids, which total about 600 in the entire protein. The difference between a normal hemoglobin molecule and a sickle cell molecule is only 2 amino acids out of the approximately 600. A person whose body only produces sickle cell hemoglobin will have symptoms of sickle cell anemia. These occur because the change of amino acids from gultamatic acid to valine causes the hemoglobin molecules to assemble into long fibers that deform the red blood cells into a disc shape to a crescent shape.
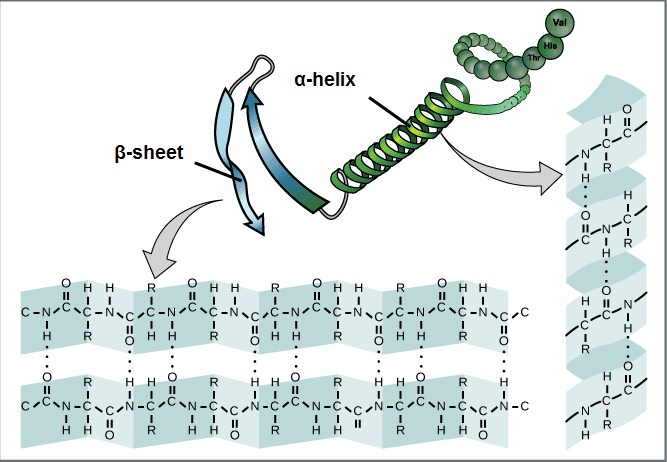
Secondary structure: The next level of protein structure refers to locally folded structures, that is, the structure that peptides adopt due to the interactions between the backbone atoms (that is, between peptide bonds). The most common types of secondary structures are the α-helix and the β-sheet. Both structures maintain their shape through hydrogen bonds, which are formed between the O of the carbonyl group of one amino acid and the H of the amino group of another.
In an α helix, the carbonyl group (C = O) of one amino acid is hydrogen bonded to the H (N-H) amino group of another amino acid four places further up the chain. This bonding pattern pulls the polypeptide chain to form a helical structure that resembles a curly ribbon, in which each turn of the helix contains 3.6 amino acids. The R groups of amino acids protrude out of the α helix, where they can freely interact with other molecules.
In a β sheet, two or more segments of a polypeptide chain are aligned next to each other, forming a lamellar structure that is held together by hydrogen bonds. These bridges are formed between the carbonyl and amino groups of the skeleton, while the R groups extend above and below the plane of the sheet. The chains of a β sheet can be parallel when pointing in the same direction or antiparallel when pointing in opposite directions.
Certain amino acids are more or less likely to be found in α-helices or β-sheets. For example, the amino acid proline is sometimes called a "helix switch," because its unusual R group (which joins the amino group to form a ring) creates a kink in the chain and is not compatible with the formation of the propeller. Proline is normally found in the folds, the unstructured regions between secondary structures. Similarly, amino acids such as tryptophan, tyrosine, and phenylalanine, which have large ring structures in their R groups, are often found in β-sheets, perhaps because their structure provides enough space for side chains.
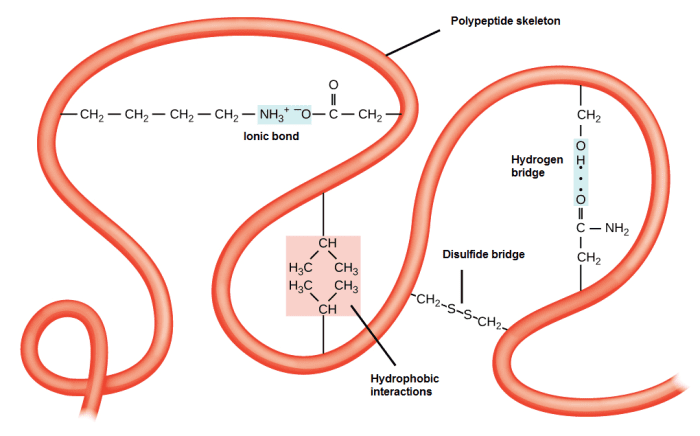
Tertiary structure: The general three-dimensional structure of a protein is generated mainly by the interactions between the R groups of the amino acids that make up proteins. The R-group interactions that contribute to tertiary structure include hydrogen bonds, ionic bonds, dipole-dipole interactions, and London scattering forces - basically, they make up the full range of non-covalent bonds. For example, R groups with similar charges repel each other, while those with opposite charges can form an ionic bond. Also, polar R groups can form hydrogen bonds and other types of dipole-dipole interactions. Hydrophobic interactions are also important for tertiary structure, as amino acids with hydrophobic nonpolar R groups clump together on the inside of the protein, leaving hydrophilic amino acids on the outside to interact with surrounding water molecules. Finally, there is a special type of covalent bond that can contribute to the tertiary structure: disulfide bridges. These covalent bonds, formed between the sulfurs in the cysteine side chains, are much stronger than the other types of bonds that contribute to the tertiary structure. They act as molecular security clips as they keep all parts of the polypeptide tightly attached to each other. It is through this whole range of bonds that peptides in their α-helix or β-sheet forms interact to form a protein.
Quaternary structure: Many proteins are made up of a single polypeptide chain and have only three levels of structure. However, some proteins are made up of several polypeptide chains, also known as subunits. When these subunits join, they generate the quaternary structure of the protein, an example is hemoglobin, which is made up of four subunits, two of the α type and two of the β type. Another example is DNA polymerase, an enzyme that synthesizes new DNA strands that is made up of ten subunits.
In general, the components and interactions of the three main structures affect to generate the quaternary structure, which is divided into two, fibrilose and globular, and the main difference is the environment in which they are found, since globular proteins can be maintained in environments liquids, while fibrillar ones are not.
Protein Denaturation and Folding: Each protein has its own unique shape. If the temperature, pH or the environment of a protein is changed or if it is exposed to chemical substances, these interactions can be altered, causing the loss of the three-dimensional structure of the protein and turning it into a chain of amino acids without structure that will float above the medium it lies on. When a protein loses its higher-order structure, but not its primary sequence, it is said to have been denatured and is no longer functional.
In some proteins, denaturation can be reversed since the primary structure of the polypeptide is still intact, in this cases it's possible that it will regain its functionality if it is returned to its normal environment. However, at other times the denaturation is permanent. An example of irreversible protein denaturation occurs when an egg is fried. The protein albumin in the liquid white becomes opaque and solid as it is denatured by the heat of the stove, and will not return to its original raw form even when cooled.
Some researchers have determined that some proteins can be refolded after denaturation even in a test tube. Since these proteins can pass themselves from an unstructured to a folded form, their amino acid sequences must contain all the information necessary for folding. However, not all proteins are capable of doing this and the way in which they fold normally in a cell appears to be more complicated. Many proteins do not fold themselves, but are helped by proteins known as chaperones (chaperonins).
© 2021 Daniela Alejandra Rodríguez Cerda














